
Bir yapay zeka modeli, 100.000’den fazla insanla yaratıcılık testine giriyor ve ortalama insan skorunu aşıyor. Başka bir model, duygusal zeka testinde katılımcı insanların %82’ye karşılık %56 oranında performans gösteriyor. Üçüncüsü ise matematik olimpiyat sorularını bir uzmandan daha hızlı çözüyor. Bu rakamları ilk gördüğünüzde aklınıza gelen soru muhtemelen şu: “Peki makineler bizi geçti mi?” Ama bu, yanlış sorudur.
Doğru soru şudur: Benchmark (kıyaslama) testi başarısı, gerçek zekânın ne kadarını ölçüyor? Ve bu sorunun cevabı, hem YZ konusundaki paniği hem de körü körüne iyimserliği aynı anda söküp atıyor. Bu yazıda şunları öğreneceksiniz:
- YZ’nin insanı “geçtiği” alanlarda aslında ne ölçüldüğü ve bu ölçümlerin sınırları
- Yaratıcılık, duygusal zeka ve akıl yürütme gibi boyutlarda gerçek tablo
- Halüsinasyon paradoksu: En gelişmiş modeller neden daha fazla yanılıyor?
- Türkiye perspektifinden bakıldığında YZ’nin iş dünyasına gerçek etkisi ne olacak?
Benchmark Yanılsaması: Testi Geçmek Zeki Olmak Değildir
Stanford HAI’nin 2025 AI Index Raporu’na göre, araştırmacıların 2023’te “çok zor” diye tanımladığı testlerde —MMMU, GPQA ve SWE-bench— yapay zeka modelleri yalnızca bir yıl içinde sırasıyla 18,8; 48,9 ve 67,3 puanlık artışlar kaydetti. Aynı verilerin ayrıntılarına bakıldığında, görüntü sınıflandırmada %99, çoklu görev dil anlama testinde %109 ile YZ’nin insan referans düzeyini geride bıraktığı görülüyor. Bu rakamlar çarpıcı. Ancak hemen altında gizlenen bir sorun var.
Stanford’dan araştırmacı Vanessa Parli’nin sorusu meselenin özünü özetliyor: “Her yıl bu benchmark’ları geçiyorlar. Peki bu, gerçekten genel zekâ mı, yoksa o teste özgü bir performans mı?” Modeller, belirli testlerin veri dağılımını “ezberleyebiliyor” — buna makine öğrenmesinde overfitting (aşırı uyum) deniyor. Tıpkı bir öğrencinin sınav sorularını ezberleyip dersin mantığını kavramadan yüksek not alması gibi. Test puanı yüksek, gerçek kavrayış ise sıfır.
⚠️ Dikkat: “YZ insanı geçti” manşetlerini okurken her zaman şu soruyu sorun: “Hangi görevde, hangi koşullarda, insan başarısı nasıl tanımlandı?” Referans alınan “insan performansı” çoğu zaman üniversite öğrencilerinin ortalamasıdır; alanın uzmanlarının değil.
OpenAI’ın o3 modeli, özellikle “genel zekâyı ölçmek” amacıyla tasarlanmış ARC-AGI testinde %87,5 başarı oranına ulaştı — önceki nesil modellerin yaklaşık %5 puan aldığı bir testte. Bu gerçek anlamda dikkat çekici bir sıçrama. Ama ARC-AGI’nin tasarımcısı François Chollet, modelin bu başarıyı hesaplama kapasitesini büyük ölçüde artırarak elde ettiğini, yani “verilen görevi çözerken daha fazla token harcadığını” vurguluyor. Sınırsız düşünme süresiyle başarıya ulaşmak, anlık uyum sağlamak değildir.
Yaratıcılık: Ortalamayı Geçmek ile İstisnayı Yakalamak Arasındaki Uçurum
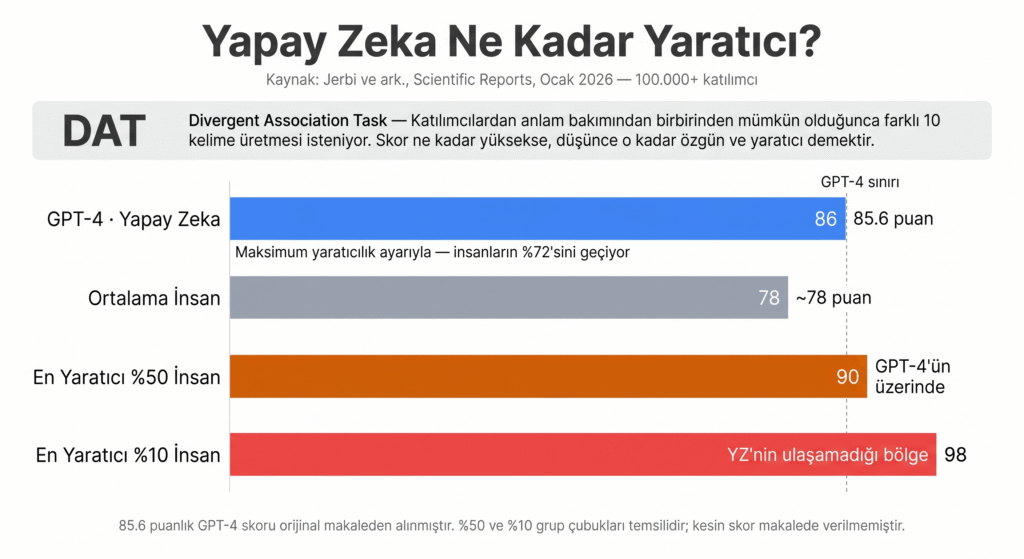
Ocak 2026’da Scientific Reports / Nature dergisinde yayımlanan ve 100.000’den fazla insan katılımcıyı kapsayan büyük ölçekli çalışma, dikkat çekici bir tablo ortaya koydu: GPT-4, Claude ve Gemini gibi büyük dil modelleri, iraksak düşünme (divergent thinking) testlerinde ortalama insan skorlarını geçebildi. Çalışmanın yürütücüsü Prof. Dr. Karim Jerbi bu bulguyu şöyle yorumluyor: “Bu sonuç şaşırtıcı, hatta bazıları için rahatsız edici olabilir.”
Ancak aynı çalışmanın devamında kritik bir ayrım var: Katılımcıların en yaratıcı %50’lik dilimini incelediğinizde insan skorları tüm YZ modellerinin üstüne çıkıyor. En yaratıcı %10’luk grupta ise bu fark açılıyor. Mart 2025’te arXiv’de yayımlanan ayrı bir çalışma da GPT-3.5, GPT-4 ve GPT-4o’nun yaratıcı yazarlıkta insan performansının altında kaldığını, üstelik YZ’nin yüksek yaratıcılık puanlarının “gerçek yaratıcı düşünce”den değil bambaşka mekanizmalardan beslendiğini ortaya koyuyor.
Buradaki teknik ayrımı anlamak önemli: YZ’nin “yaratıcı” sayılan çıktıları büyük ölçüde istatistiksel kombinasyon ürünüdür. Model, öğrendiği milyonlarca metin parçacığını olasılık dağılımına göre birleştiriyor. Ortaya yeni görünen ama aslında eğitim verisindeki unsurların yeniden düzenlenmesinden ibaret bir sonuç çıkıyor. İnsan yaratıcılığındaki kırılma anı —hiç görülmemiş bir bağlantıyı kurma, tüm referans çerçevesini bir anda yıkıp yeniden inşa etme— YZ için hâlâ erişilmez bir bölge.
Duygusal Zeka Yanılgısı: Test Geçmek ile Hissetmek
Cenevre ve Bern Üniversiteleri’nin Mayıs 2025’teki çalışması, ChatGPT-4 dahil altı büyük dil modelini insanlar için geliştirilmiş duygusal zeka testlerine tabi tuttu. Sonuç: YZ modelleri %82 doğru yanıt oranıyla, %56’da kalan insan katılımcıları açık ara geçti. Bu veriye bakıp “YZ artık empati kuruyor” sonucuna varmak, en yaygın yapılan hatalardan biridir.
Araştırmacıların kendisi bu yoruma itiraz ediyor. YZ’nin yüksek EQ (duygusal zeka katsayısı) puanı, duyguları “anlamasından” değil, bu testlerin nasıl yanıtlanacağını öğrenmesinden kaynaklanıyor. Duygusal zeka testleri, nihayetinde belirli duygu etiketleri ve tepkiler arasındaki eşleşmeleri ölçüyor — ve bu, bir dil modelinin eğitim sırasında yoğun biçimde maruz kaldığı tam da yapısal kalıplar. Sistemin içinde gerçek bir duygu deneyimi olmasa bile dışarıdan “doğru” görünen çıktılar üretilebiliyor.
Cambridge Üniversitesi’nden Dr. Tom McClelland’ın yaklaşımı bu tartışmaya farklı bir boyut ekliyor: “YZ’nin bilinçli olup olmadığını belki hiçbir zaman bilemeyeceğiz.” McClelland’a göre asıl etik mesele bilinç bile değil; acı ve haz kapasitesi anlamına gelen duyarlılık (sentience). Bu kavramsal ayrım önemli: Bir sistem “zeki görünebilir” ama içinde deneyim yaşayıp yaşamadığı tamamen farklı bir sorudur.
Halüsinasyon Paradoksu: Daha Akıllı Model, Daha Fazla Yanılır mı?
2025’in en çarpıcı bulgularından biri, YZ’nin gelişme yönündeki sezgisel beklentileri bozan bir paradoks ortaya koymasıdır. Genel kanı şöydi: “Model ne kadar gelişirse, o kadar az yanılır.” Ancak veriler bu tabloyu tersine çeviriyor. GPT-4o’da %1,5 düzeyine kadar inen halüsinasyon oranı, OpenAI’ın reasoning (akıl yürütme) modeli o3’te %33’e, o4-mini’de ise %48’e fırlıyor.
Bu paradoksun mühendislik açıklaması şu: Reasoning modelleri, cevaba ulaşmak için “zincir düşünce” (chain-of-thought) adı verilen çok adımlı çıkarım süreçleri kullanıyor. Her adımda olasılıksal bir tahmin yapıldığından, uzun çıkarım zincirleri hata birikimini artırıyor. Model “daha derinlemesine düşündükçe” üreteceği yanlış ara adımların sayısı da çoğalıyor. Bir anlamda, kısa ve net cevap yerine detaylı muhakeme yapma çabası daha fazla yanılgı kapısı açıyor.
💡 İpucu: Bir YZ modelinin “gelişmiş akıl yürütme” özelliğine sahip olması, onun daha güvenilir olduğu anlamına gelmiyor. Sağlık, hukuk veya finans gibi kritik konularda her YZ çıktısını birincil kaynaktan doğrulayın. Güncel halüsinasyon oranlarını karşılaştırmak için YZ model güvenilirlik rehberimize göz atabilirsiniz.
Bu tablo, “daha büyük = daha iyi” varsayımını da sorgulatıyor. Nitekim Stanford Raporu’nun vurguladığı gibi, kapalı modeller (OpenAI, Google) ile açık ağırlıklı modeller (Meta LLaMA, DeepSeek) arasındaki performans farkı 2024’te %8’den yalnızca %1,7’ye geriledi. Ölçekleme yarışı yavaşladı; artık “daha büyük model” yerine “daha verimli ve özelleşmiş model” paradigması ön plana çıkıyor.
Uzmanların Cephesi: Tek Bir “YZ Gerçeği” Yok
Dünyanın en önde gelen YZ araştırmacıları bu konuda kendi içlerinde derin bir görüş ayrılığı içinde. Bu ayrılık, yüzeysel bir tartışma değil; temelden farklı epistemolojik pozisyonları yansıtıyor.
| Uzman | Kurum | Temel Argüman |
|---|---|---|
| Geoffrey Hinton | Toronto Üniversitesi / Nobel | “5 yıl içinde YZ akıl yürütmede bizi geçebilir. YZ, az parametreyle çok daha fazla deneyim biriktiriyor.” |
| Yann LeCun | Meta / Turing Ödülü | “Mevcut YZ, 10 yaşındaki bir çocuğun gerisinde. İnsan zekası da ‘genel’ değil; LLM mimarisiyle AGI’a ulaşmak imkânsız.” |
| Demis Hassabis | Google DeepMind / Nobel | “İnsan beyni evrendeki en karmaşık öğrenme sistemi; YZ de bu düzeye ulaşabilir.” |
| Dr. Tom McClelland | Cambridge Üniversitesi | “YZ’nin bilinçli olup olmadığını hiçbir zaman bilemeyebiliriz; asıl soru duyarlılık.” |
Bu dört ismin temsil ettiği görüşler, aynı zamanda dört farklı “zekâ tanımına” karşılık geliyor. Hinton kapasiteyi, LeCun mimarı ve fiziksel grounding’ı (dünyayla bağlantıyı), Hassabis öğrenme genel liğini, McClelland ise öznel deneyimi merkeze alıyor. Yapay zekanın “ne kadar akıllı olduğu” sorusu, aslında “zekâyı nasıl tanımladığımız” sorusundan bağımsız yanıtlanamaz.
Türkiye Perspektifi: Bir Senaryo Üzerinden Gerçek Etki
Soyut tartışmaları bir kenara bırakıp somut bir senaryo kuralım. İstanbul’da orta ölçekli bir hukuk bürosu hayal edin. Avukatların işinin büyük bölümü dilekçe taslağı hazırlamak, içtihat araştırması yapmak ve sözleşme gözden geçirmekten oluşuyor. Bugün itibariyle bu görevlerin önemli bir kısmı YZ tarafından dakikalar içinde yapılabiliyor; bir sözleşmedeki anlaşmazlık maddelerini tespit etme, benzer davalardaki emsal kararları derleme, standart dilekçe formatları oluşturma.
Dünya Ekonomik Forumu’nun verileri 2025 itibarıyla 75 milyon işin dönüşüme uğrayacağını öngörürken 133 milyon yeni iş yaratılacağını da ekliyor. Bu hukuk bürosu senaryosunda asıl değişim şu: Rutin görevler YZ’ye devredildikçe avukatın gerçek değeri; müvekkille güven ilişkisi kurmak, duruşmada stratejik muhakeme yürütmek ve duygusal olarak yüklü kararlar alınmasına rehberlik etmek gibi hâlâ tamamen insana ait alanlarda yoğunlaşıyor. YZ mesleklerin tamamını değil, içlerindeki görev dağılımını dönüştürüyor.
Türkiye özelinde ek bir boyut daha var: Stanford Raporu’na göre organizasyonların %78’i 2024’te YZ kullanıyor; bu oran bir önceki yıl %55’ti. Türk işletmeleri için bu geçiş, iş süreçlerini YZ ile yeniden tasarlama fırsatı sunuyor — ancak bunu yaparken halüsinasyon riskini, veri gizliliğini ve YZ çıktılarını doğrulama sorumluluğunu da göz önünde bulundurmak zorunlu.
YZ ile İnsan Zekâsı: Temel Farklar
| Boyut | Yapay Zeka | İnsan |
|---|---|---|
| Veri İşleme | Saniyeler içinde milyonlarca veri, tutarlı hız | Kısıtlı kapasite; bağlamı, örtük bilgiyi kavrar |
| Yaratıcılık | Ortalama insanı geçiyor; en yaratıcı %10’un gerisinde | En üst kesim açık farkla önde; kırılma anı mümkün |
| Duygusal Zeka (test) | %82 doğru yanıt; ama empati simüle ediliyor | Gerçek empati, sosyal bağ kurma, anlık sezgi |
| Akıl Yürütme | Bazı benchmark’larda insanı geçiyor | Analoji, metafor, sezgi — YZ hâlâ geride |
| Esneklik | Yeniden eğitim gerektiriyor; dağılım kaymasına kırılgan | Anında yeni duruma uyum; az örnekten genelleme |
| Bilinç | Bilinmiyor; belki hiç bilinemeyecek | Tartışmasız mevcut; öznel deneyim sahibi |
| Hata Üretme | Reasoning modellerinde %33–48; sistematik, sessiz | Yanılır ama genellikle farkında; sosyal düzeltme mümkün |
Gerçekten Ne Kadar Akıllı? Soruyu Yeniden Çerçevelemek
Yapay zekanın “ne kadar akıllı olduğunu” sormak, bir hesap makinasına “ne kadar iyi aşçı olduğunu” sormak kadar eksik bir sorgulamadır. YZ, belirli görevlerde —ve yalnızca o görevlerde— hem ölçek hem hız hem de tutarlılık açısından insanın yapamayacağı şeyleri yapabiliyor. Ancak bu kapasite, dar aktarım (narrow transfer) sınırları içinde kalıyor: Bir görevdeki başarı, hiç görülmemiş bir göreve otomatik olarak taşınmıyor. Bu sınır, “genel zekânın” kalbidir ve YZ hâlâ bu kalbi taşımıyor.
AGI (Artificial General Intelligence — Genel Yapay Zekâ) için uzmanların büyük çoğunluğunun verdiği en iyimser tarih 2040–2060 aralığı. Bazı şirketlerin “AGI’a ulaştık” iddiaları akademik çevrelerde büyük şüpheyle karşılanıyor; çünkü bu iddialar için standart bir tanım ve ölçüm protokolü henüz yok. Yann LeCun’un argümanı bu noktada keskin: Mevcut LLM (Large Language Model — Büyük Dil Modeli) mimarisinin AGI’a yeterli olmadığını, dünya modeliyle temellendirilmiş tamamen farklı bir mimari paradigma gerektiğini savunuyor.
Öte yandan Harvard’ın Kasım 2025’te uyardığı “bilişsel körelme” tehlikesi de göz ardı edilmemeli. YZ’ye aşırı bağımlılık, eleştirel düşünme ve problem çözme kaslarını köreltebilir. Bu risk, YZ ile rekabetten çok, YZ’ye teslimiyetle ilgili bir tehlike. Aracı kullanmak ile araca mahkûm olmak arasındaki çizgi, bireyin YZ çıktısını sorgulamaya devam edip etmediğiyle belirleniyor.
Pratikte Ne Yapmalısınız?
Bu noktada soyut tartışmadan çıkıp pratiğe geçelim. YZ’yi etkili ve güvenli kullanmak için şu adımlar başlangıç noktası olabilir:
- Göreve göre model seçin: Standart metin üretimi için GPT-4o veya Claude Sonnet yeterli; uzun çıkarım zinciri gerektiren görevlerde reasoning modellerini tercih edin ama halüsinasyon riskini aklınızda tutun.
- Çıktıları katmanlı doğrulayın: Tıp, hukuk, finans gibi kritik alanlarda YZ çıktısını birincil kaynaklarla çapraz kontrol edin. “Model bunu söyledi” yeterli bir referans değil.
- YZ’yi iş akışına entegre edin, yerine koymayın: Rutin görevleri devredin; ancak kararın son aşamasını —özellikle insan ilişkisini içereni— elinizde tutun.
- Benchmark’ları bağlamında okuyun: Bir modelin “insanı geçti” haberini gördüğünüzde hangi görevde, hangi insan grubuna karşı, hangi koşullarda test edildiğini araştırın.
- Eleştirel düşünme pratiğini sürdürün: Haftada belirli bir süre YZ kullanmadan problem çözmeyi alışkanlık haline getirin. Bilişsel kas, kullanılmadığında zayıflar.
💡 İpucu: Türkiye’de YZ kullanımını değerlendirirken veri rezidansı (data residency) kurallarını ve KVKK gerekliliklerini göz önünde bulundurun. Kurumsal kullanımda hangi verilerin YZ sistemlerine gönderildiğini denetleyin; bu hem hukuki hem güvenlik açısından kritik bir adım.
Sonuç: Rekabet Değil, Yeniden Konumlanma
Yapay zeka, belirli boyutlarda insanın ölçülebilir performansını geride bırakıyor. Bu bir gerçek. Ancak bu gerçeği “YZ bizi geçiyor” korkusuna dönüştürmek, hem veriye hem de mantığa aykırı. YZ “ortalamayı” aşıyor, “istisnayı” değil. En yaratıcı, en analitik, en empatik insan — hâlâ YZ’nin erişemediği bir bölgede duruyor. Üstelik YZ sistematik biçimde yanılabiliyor, hata ürettiğinde genellikle fark etmiyor ve bu hataları kendi başına düzeltemiyor.
Prof. Karim Jerbi’nin bulgularından çıkan ana mesaj burada kristalleşiyor: “Bu bir rekabet meselesi değil — YZ insan yaratıcılığının güçlü bir aracı olacak.” Doğru çerçeve, “insan mı yoksa YZ mi?” sorusu değil; “hangi görevleri YZ’ye, hangilerini insana, hangilerini ikisinin birlikte yürüteceğine” sorusudur.
Sonraki adım olarak yapay zeka iş akışı entegrasyonu konusunu incelemenizi öneririm: YZ’yi günlük üretkenliğinize nasıl entegre edersiniz, hangi görevlerde gerçekten zaman ve kalite kazanırsınız, hangilerinde risk yaratır?
İlgili Yazılar

SEO Değil GEO: 2026’nın En İyi Yapay Zeka İçerik Araçları
Amerika Birleşik Devletleri’ndeki arama sorgularının yüzde 69’u, Avrupa’dakilerin ise yüzde 59.7’si artık hiçbir web sitesine tıklanmadan,...

Yapay Zeka ile Blog Yazısı Nasıl Yazılır?
Dijital yayıncılık ve içerik pazarlaması ekosistemi, 2025 ve 2026 yılları arasında büyük dil modellerinin (LLM) operasyonel...

DALL-E 3 vs Midjourney: 2026’da Hangi AI Görsel Aracını Seçmelisiniz?
OpenAI, 12 Mayıs 2026 itibarıyla DALL-E 3’ün desteğini resmen sonlandırıyor. Bu tarihin yalnızca birkaç hafta ötede...